
Cuando hablamos de integración continua acabamos discutiendo sobre Jenkins y cómo configurar sus plugins. Nos perdemos hablando las herramientas. La integración continua tiene que darnos la confianza de que nuestro software está preparado para entrar en producción. Si no tenemos esta sensación es que las herramientas no nos dejan ver el bosque.
¿De dónde viene Integración Continua?
Una aplicación está compuesta de diferentes piezas de software. Podemos llamar estas piezas módulos, componentes, microservicios o gallifantes. Y para que la aplicación funcione es necesario que todas las piezas encajen.
Hace unos años era habitual que cada equipo desarrollara por separado una parte de la aplicación. En las fases finales del proyecto se planificaba una etapa de integración para juntar todas las piezas. Y se planificaba mucho tiempo.
Aunque ahora somos más ágiles, seguimos sufriendo este proceso de integración. La situación más habitual es cuando llevamos tiempo sin publicar código y al intentar subirlo tenemos que ponernos al día o coloquialmente: “me he tragado un merge de la muerte”.
Retrasamos la salida de nuestra aplicación por problemas técnicos imprevistos (“estas piezas no enganchan”) o por falta de confianza (“han cambiado muchas cosas, no sé si va a funcionar”). Limitamos cuándo y cómo se puede actualizar la aplicación para mantener el control. Sacrificamos nuestra agilidad.
¿Cómo podemos evitarlo? No podemos. Simplemente integramos un poco todos los días, es decir, integración continua: “if something hurts, do it more often” (si algo duele, hazlo más a menudo).
¿Qué necesitamos para la integración continua?
Nuestra aplicación tiene que adaptarse a los cambios. Para introducir nuevos cambios necesitamos saber, lo antes posible, que la aplicación sigue comportándose correctamente. Es decir, la nueva funcionalidad que se introduce funciona y no rompe ninguna funcionalidad anterior.
Necesitamos pruebas automatizadas. Los cambios han de acompañarse de pruebas que validan la nueva funcionalidad y se ejecutan junto con las pruebas anteriores. No es estrictamente necesario aplicar Test Driven Development (codificar las pruebas antes que el cambio en sí) pero sí hacerlas.
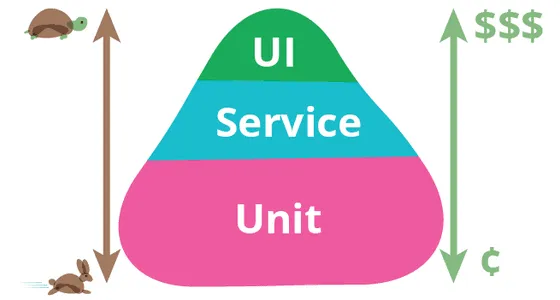
La teoría de pruebas suele distinguir entre unitarias, de integración y de sistema. Pruebas que no requieren de otras piezas, que sí requieren de otras piezas y que necesitan la aplicación completa, respectivamente. La recomendación es que se repartan 70% a unitarias, 20% a integración y 10% a sistema.
Hacer pruebas unitarias es sencillo. El problema son las de integración y de sistema que son un auténtico dolor ya que exigen mucho esfuerzo y tienden a romperse con mayor facilidad. Por eso se favorecen las pruebas unitarias.
Una vez tenemos nuestras pruebas, y somos capaces de ejecutarlas, el siguiente paso es automatizar el proceso.
Visto en GitHub: integrando un proyecto sencillo
Queremos que cualquier cambio en el código pase las pruebas y se nos notifique el resultado. Para ello haremos que nuestra herramienta de integración continua esté atenta a los cambios del repositorio.
Es lo que habitualmente vemos en proyectos open-source hospedados en GitHub. El proyecto hace una integración con Travis CI de tal forma que todos los pull request provocan una ejecución de la pruebas. El resultado de las pruebas se adjunta al pull request.
Si nuestra aplicación es sencilla y casi no tiene dependencias (como una libería open-source) podemos conformarnos con este escenario. Prácticamente con pruebas unitarias podemos validar la aplicación entera.
Sin embargo es más probable que tengamos dependencias que hagan que las pruebas de integración requieran de otras piezas.
Integrando aplicaciones menos sencillas
Imaginemos una aplicación web. Podría tener las siguientes piezas:
- Single Page Application, construido con React.
- Balanceador, por ejemplo HAProxy.
- Backend, construido con Ruby on Rails.
- Persistencia, por ejemplo MongoDB.
- Cola de mensajes, por ejemplo RabbitMQ.
- Trabajos en segundo plano, construido con Sidekiq.
Aún siendo una aplicación con pocas dependencias hemos complicado nuestras necesidades de integración. Ahora no solamente necesitamos controlar los cambios de código, además necesitamos controlar los cambios de las dependencias y de la configuración.
La teoría nos anima a utilizar diferentes técnicas para tratar este escenario. Sin embargo estamos en ese punto intermedio en el que el esfuerzo nos parece injustificable “solamente para hacer bien tests”. No es que defienda esta línea de pensamiento pero vivimos en un mundo de lágrimas.
En el caso hipotético anterior haríamos lo siguiente:
- Separar en dos proyectos de integración: uno para probar la Single Page Application y otro para el resto.
- Establecer una API entre la Single Page Application y el Backend. Es un paso necesario en cualquier caso, solo que aquí lo utilizamos como un contrato: una excusa para no probar automáticamente ambas piezas juntas.
- Trasladar toda la complejidad a la herramienta de integración. De alguna forma la herramienta ha de crear (y manenter) un entorno de pruebas en el que desplegar todas las piezas.
Es un escenario sencillo de construir que cumple aunque con restricciones. Cualquier pieza que se quede inestable, por ejemplo registros en la base de datos, puede obligarnos a realizar correcciones manuales e impide que podamos ejecutar varias pruebas al mismo tiempo.
Bienvenidos al mundo de los microservicios
Si nuestra pieza de Backend se convierte en múltiples microservicios las cosas se complican. Ahora tenemos más piezas y muchas más dependencias con lo que hacer pruebas de integración es más exigente.
La solución pobre es mantener el API entre microservicios como contratos. Aunque las pruebas unitarias ayudan, una vez en producción pueden ocurrir situaciones curiosas.
Volvamos a la esencia de las pruebas de integración. Para comprobar que una pieza funciona necesitamos sus dependencias. Si una pieza no tuviera dependencias podríamos pasar sus pruebas unitarias y a partir de entonces utilizarla en las de integración de las que dependan de ella. Si no queremos perder la cordura es necesario que podamos construir las pruebas de integración de abajo arriba. No podemos permitir dependencias cíclicas.
Necesitamos separar dos fases para cada pieza: una fase para las pruebas unitarias y otra para las pruebas de integración. Ahora podemos configurar nuestra herramienta de integración para que:
- Cuando el código de una pieza cambie queremos que se ejecuten sus pruebas unitarias, se cree un entorno con la última versión válida de sus dependencias y se ejecute su prueba de integración.
- Cuando la pieza ha superado su prueba de integración, todas las piezas que dependan de ella ejecutarán sus pruebas de integración contra la nueva versión.
De esta forma aseguramos que podemos ponerla en producción.
Ahora bien, ¿tenemos la capacidad crear estos entornos en los que ir desplegando nuestras piezas poco a poco? Si estamos trabajando con microservicios deberíamos disponer de las herramientas de despliegue y orquestación necesarias.
O puede que no. Puede que adaptar las herramientas sea demasiado costoso o innecesariamente complicado. Así que volveríamos a tener un conjunto de máquinas en las que podamos desplegar cada pieza y realizar las pruebas necesarias.
¡Nos faltan las pruebas de sistema!
Hasta el momento nos hemos centrado en automatizar las pruebas unitarias y hemos visto la complejidad para automatizar las de integración. ¿Qué necesitamos para las de sistema?.
Estamos hablando de pruebas de rendimiento, de stress, de usabilidad, de aceptación, etc. Realizarlas de forma automática exige mucha madurez. O dicho de otra manera, mucha gente y mucho tiempo.
Lo más habitual es automatizar estrictamente lo necesario. En esta fase nos preocupamos de que nuestras herramientas de devops son capaces de replicar la infraestructura de producción, a una escala menor normalmente.
Una vez disponemos de una réplica con la última versión de las piezas se realizan pruebas de forma manual. Aquí podría entrar el departamento de calidad (QA) para validar la aplicación.
De hecho esta fase se suele configurar en la herramienta de integración para que cada paso implique intervención humana. Pensad que si estamos probando la applicación queremos congelar las actualizaciones hasta que terminemos.
Un ejemplo de revisión podría ser:
- Abrir un ticket de nueva release.
- Crear una réplica de producción (de forma automática).
- Realizar las pruebas.
- Cerrar el ticket de la nueva release.
Si queremos automatizar en este fase normalmente hacemos un smoke test. Un smoke test simplemente pone todo en funcionamiento, hace una petición sencilla y espera a ver si algo arde en llamas. Nos garantiza que al menos la aplicación arranca.
Las pruebas de carga y de rendimiento suelen exigir un nivel alto en la gestión de operaciones. Podríamos generar carga, o reutilizar peticiones copiadas de producción, monitorizar cómo se comporta la aplicación y evaluar los umbrales.
Vale, ¿cuándo desplegamos?
La integración continua debe darnos confianza para actualizar la aplicación. Realmente esta es la base de lo que conocemos como Continuous Delivery.
El Continuous Delivery nos va a fijar un conjunto de piezas que pasan las pruebas y que por tanto pueden ser desplegadas en producción en cualquier momento. Pero no necesariamente han de ser desplegadas. Es un modelo pull donde elegimos cuándo queremos realizar este paso. De hecho es habitual que la herramienta de integración tenga un botón que haga el despliegue a producción.
También podemos hacer que todo lo que supere las pruebas se despliegue automáticamente. Este modelo push lo llamamos Continuous Deployment. Todo lo que parece funcionar va directo a explotación.
Incluso aquí podemos seguir ampliando nuestras pruebas emparejándolas con técnicas de despliegue. Por ejemplo utilizar un canary, poner en producción una pieza para ver si funciona o no y después actualizar el resto. O plantear un despliegue Blue/Green en el que desplegamos una réplica de producción con la nueva versión y pivotamos para ver si funciona.
Conclusiones y recomendaciones
Hemos visto como la base de la integración continua se basa en la automatización de pruebas. Cada tipo de prueba tiene sus requisitos y sus formas de abordarla. Pero no hay un acercamiento genérico que valga para todos los proyectos.
Mi recomendación es ir profundizando en cada fase según nos vaya aportando valor.
Al comienzo de un proyecto es necesario que todos los desarrolladores sean capaces de ejecutar las pruebas unitarias. Si es un proceso complejo nos acostumbraremos a que las pase la herramienta de integración y hará que nuestros ciclos de depuración sean más largos.
Otra práctica recomendada es hacer cambios pequeños cada vez (e integrar todo el rato). Es más fácil encontrar la causa de que un test falle en 100 líneas que en 3000.
Con todas las piezas pasando sus pruebas es momento de revisar cómo afrontamos las pruebas de integración. Es diferente provisionar una base de datos para una pieza de backend que disponer de la API para probar una aplicación móvil.
Aquí debemos elegir una herramienta de integración que se ajuste a nuestra forma de trabajar y que nos permita, de la forma más clara posible, establecer qué falla y por qué. Si nuestra aplicación móvil falla queremos saber que el culpable es el nuevo microservicio de facturación.
Una vez todas las piezas parecen encajar tenemos que replicar un entorno de producción para hacer el resto de las pruebas. Automatizar el despliegue nos va a dar confianza a la hora de actualizar o incluso cuando tengamos problemas más drásticos en producción.
Evidentemente no es necesario hacerlo de forma sencuencial. Podemos definir una fase que simplemente haga un echo “Integrado” para poder ver la estructura. Pero sí ir profundizando en orden.
Este ejemplo bastante completo de Architecting for Continuous Delivery es un buen resumen.
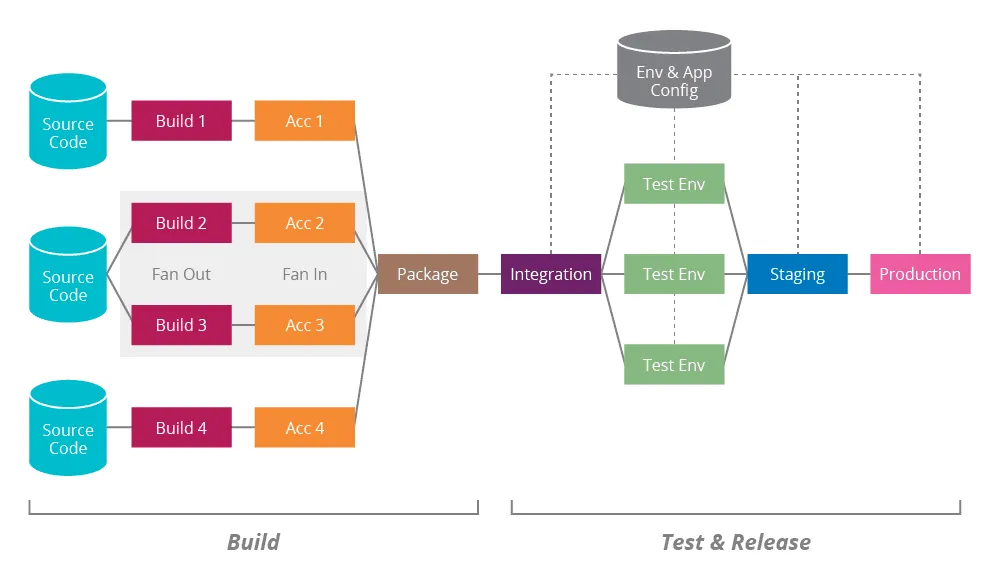
Hasta aquí todo lo que quería contaros sobre la integración continua. Si os fijáis no he mencionado ninguna herramienta en concreto. Sinceramente creo que la herramienta es lo de menos, lo importante es que vuestro proceso de integración os transmita confianza.
Otras referencias: